之前已经有文章介绍过 MapReduce ,这是一个并发处理的利器。而 fx 是一个完备的流式处理组件。
和 MapReduce 类似的,fx 也存在并发处理的函数:Parallel(fn, options)。但同时它也不只有并发处理。From(chan) ,Map(fn),Filter(fn),Reduce(fn) 等,从数据源读取成流,到处理流数据,最后聚合流数据。是不是有点像 Java Lambda ,如果你之前是 Java 开发者,看到这也就明白整个基本设计。
整体API
还是从整体上概览 fx 到底是怎么构建的:
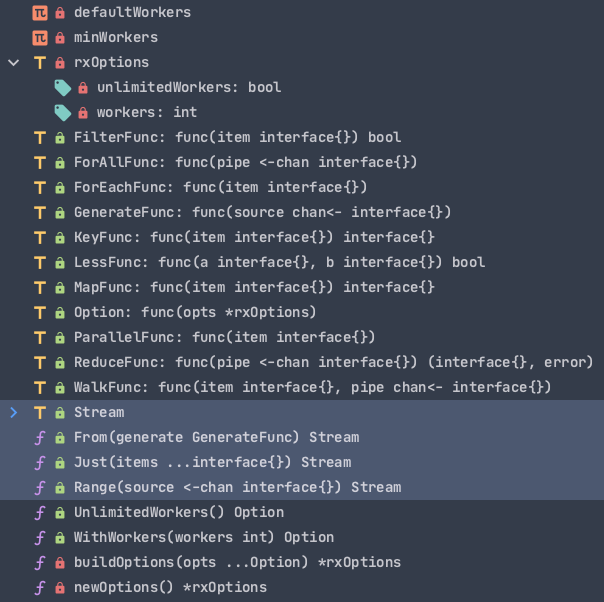
被标注的部分就是整个 fx 最重要的部分:
- 由
From(fn)这类API,产生数据流Stream
- 对
Stream转换,聚合,求值的API集合
所以列举出目前支持的 Stream API:
| API | 作用 |
Distinct(fn) | fn中选定特定item类型,对其去重 |
Filter(fn, option) | fn指定具体规则,满足规则的element传递给下一个 stream |
Group(fn) | 根据fn把stream中的element分到不同的组中 |
Head(num) | 取出stream中前 num 个element ,生成一个新的stream |
Map(fn, option) | 将每个ele转换为另一个对应的ele, 传递给下一个 stream |
Merge() | 将所有ele合并到一个slice中并生成一个新stream |
Reverse() | 反转stream中的element。【使用双指针】 |
Sort(fn) | 按照 fn 排序stream中的element |
Tail(num) | 取出stream最后的 num 个element,生成一个新 stream。【使用双向环状链表】 |
Walk(fn, option) | 把 fn 作用在 source 的每个元素。生成新的 stream |
不再生成新的 stream,做最后的求值操作:
| API | 作用 |
ForAll(fn) | 按照fn处理stream,且不再产生stream【求值操作】 |
ForEach(fn) | 对 stream 中所有 element 执行fn【求值操作】 |
Parallel(fn, option) | 将给定的fn与给定的worker数量并发应用于每个
|
Reduce(fn) | 直接处理stream【求值操作】 |
Done() | 啥也不做,等待所有的操作完成 |
如何使用
result := make(map[string]string)
fx.From(func(source chan<- interface{}) {
for _, item := range data {
source <- item
}
}).Walk(func(item interface{}, pipe chan<- interface{}) {
each := item.(*model.ClassData)
class, err := l.rpcLogic.GetClassInfo()
if err != nil {
l.Errorf("get class %s failed: %s", each.ClassId, err.Error())
return
}
students, err := l.rpcLogic.GetUsersInfo(class.ClassId)
if err != nil {
l.Errorf("get students %s failed: %s", each.ClassId, err.Error())
return
}
pipe <- &classObj{
classId: each.ClassId
studentIds: students
}
}).ForEach(func(item interface{}) {
o := item.(*classObj)
result[o.classId] = o.studentIds
})From()从一个slice生成stream
Walk()接收与一个stream,对流中每个ele转换重组,生成新的stream
- 最后由
求值操作把stream输出(fmt.Println),存储(map,slice),持久化(db操作)
简要分析
fx 中的函数命名语义化,开发者只需要知道业务逻辑需要什么样的转换,调用与之匹配的函数即可。
所以这里只简要分析几个比较典型的函数。
Walk()
Walk() 在整个 fx 被多个函数当成底层实现,Map(), Filter() 等。
所以本质就是:Walk() 负责并发将传进来的函数作用在 输入流 的每个 ele,并 生成新的 stream。
跟到源码,分成两个子函数:自定义 worker 数,默认 worker 数
// 自定义 workder 数
func (p Stream) walkLimited(fn WalkFunc, option *rxOptions) Stream {
pipe := make(chan interface{}, option.workers)
go func() {
var wg sync.WaitGroup
// channel<- 如果达到设定workers数,channel阻塞,从而达到控制并发数。
// 简易的 goroutine pool
pool := make(chan lang.PlaceholderType, option.workers)
for {
// 每一次for循环都会开启一个goroutine。如果达到workers数,从而阻塞
pool <- lang.Placeholder
item, ok := <-p.source
if !ok {
<-pool
break
}
// 使用 waitgroup 保证任务完成的完整性
wg.Add(1)
threading.GoSafe(func() {
defer func() {
wg.Done()
// 归还
<-pool
}()
fn(item, pipe)
})
}
wg.Wait()
close(pipe)
}()
return Range(pipe)
}- 使用
有缓冲channel做并发队列,限制并发数
waitgroup保证任务完成的完整性
另外一个 walkUnlimited():也使用了 waitgroup 做并发控制,因为没有自定义并发数限制,所以也就没有另外一个 channel 做并发数控制。
Tail()
介绍这个主要是里面运用了 ring 这个双向链表,其中的简单算法还是很有意思的。
func (p Stream) Tail(n int64) Stream {
source := make(chan interface{})
go func() {
ring := collection.NewRing(int(n))
// “顺序”插入,源的顺序和ring的顺序一致
for item := range p.source {
ring.Add(item)
}
// 取出 ring 中全部的 item
for _, item := range ring.Take() {
source <- item
}
close(source)
}()
return Range(source)
}至于为什么 Tail() 可以做到把源的后n个取出来,这个就留给大家去细品了。这里给出我的理解:

假设有以下这个场景,
Tail(5)
stream size:7
ring size:5这里可以使用把环状链表拉开的方式,环转线,此时以全部长度划分对称轴,翻转多余的元素,之后的元素就是
Tail(5)需要的部分了。这里采用图的方式更清晰的表现,不过代码大家也要看看。算法要考的
Stream Transform Design
分析整个 fx ,会发现整体设计遵循一个设计模版:
func (p Stream) Transform(fn func(item interface{}) interface{}) Stream {
// make channel
source := make(chan interface{})
// goroutine worker
go func() {
// tranform
for item := range p.source {
...
source <- item
...
}
...
// 关闭输入,但是依然可以从这个 stream 输出。防止内存泄漏
close(source)
}()
// channel -> stream
return Range(source)
}channel作为流的容器
- 开
goroutine对source做转换,聚合,输送到channel
- 处理完毕,
close(outputStream) channel -> stream
总结
到这就把 fx 基本介绍完了,如果你对其他API源码感兴趣,可以跟着上面的 API 列表挨个读一读。
同时也建议大家把 java stream 的API大致看看,对这种 stream call 理解可以更加深 。
同时在 go-zero 中还有很多实用的组件工具,用好工具对于提升服务性能和开发效率都有很大的帮助,希望本篇文章能给大家带来一些收获。


